Proyek ANEMLL Mengungkap Kinerja Campuran Apple Neural Engine untuk Inferensi LLM
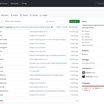
Benchmark llama3.2 pada mesin saya; M1 Max 47t/s, 1,8 watt, M4 Pro 62t/s, 2,8 watt....Apple Neural Engine ANE telah lama menjadi komponen misterius dalam chip Apple Silicon, dengan dokumentasi...Diskusi komunitas mengungkapkan frustrasi dengan pendekatan Apple terhadap akselerasi AI....Seorang pengguna melaporkan bahwa pada M4 Pro, model Llama 3.2 1B mencapai sekitar 62 token per detik...Perbandingan Kinerja: ANEMLL vs MLX pada M4 Max Framework Model Kinerja Penggunaan Memori...ANE Llama 3.2 47 tok/detik 1,8 watt M4 Pro ANE Llama 3.2 62 tok/detik 2,8...Sebuah benchmark yang menjalankan DeepSeek R1 pada M4 Max menunjukkan ANEMLL hanya mencapai 9,3 token...Bahkan framework MLX milik Apple sendiri tidak mendukung ANE, menimbulkan pertanyaan tentang strategi...GPU dua kali lebih cepat bahkan lebih cepat pada Max, tetapi menggunakan daya jauh lebih banyak 20...Meskipun makalah penelitian Apple sendiri mengklaim peningkatan kinerja yang signifikan untuk model yang...Seiring Apple terus mengembangkan perangkat kerasnya dengan chip M yang lebih baru, keseimbangan...dan mengembangkan pendekatan jendela geser untuk cache key. Pendekatan Ekosistem Tertutup Apple...bit DeepSeek R1 31,33 tok/detik 8,5GB MLX bf16 DeepSeek R1 27,17 tok/detik 15,7GB...Perangkat Keras Model Kinerja Penggunaan Daya M1 Max...implementasi ANE sangat berharga untuk menjalankan model pada perangkat dengan memori terbatas, seperti iPhone...Proyek ANEMLL merupakan langkah penting untuk membuat Apple Neural Engine lebih mudah diakses oleh pengembang